项目介绍
中国海洋石油是爬取的第一个企业,之后依次爬取了,国家电网,中国邮政,这三家公司的源码并没有多大难度,
采购信息地址:
国家电网电子商务平台
中国海洋石油集团有限公司
中国邮政
项目地址:
https://github.com/code-return/Crawl_faw
实现过程与方法
1.中国海洋石油集团有限公司
中海油的信息页面很友好,并没有多大难度,实现顺序如下:
#获取首页内容def get_one_page(url): ...#解析网页def parse_one_page(html): ...#获取最大页码def getMaxpage(html): ...#获取二级页面的文本内容def getContent(url): ...#主函数def main(): url = "https://buy.cnooc.com.cn/cbjyweb/001/001001/moreinfo.html" html = get_one_page(url) parse_one_page(html) page_num = getMaxpage(html) #拼接翻页的url,并返回翻页的源代码 for i in range(2,page_num + 1): next_url = url.replace('moreinfo',str(i)) next_html = get_one_page(next_url) parse_one_page(next_html) 在主函数中需实现翻页爬取的功能,这里通过先获取网页最大页码,然后根据页码设置循环,我们从第二页开始解析网页。
在网页解析函数parse_one_page(html)中,主要实现,获取网页中的标题,发布时间,href,获取该内容之后对数据进行筛选,存储
def time_restrant(date): # 时间判断函数,判断是否当年发布的消息 thisYear = int(datetime.date.today().year) thisMonth = int(datetime.date.today().month) thisday = int(datetime.date.today().day) year = int(date.split('-')[0]) month = int(date.split('-')[1]) day = int(date.split('-')[2]) #if ((thisYear - year <= 1) or (thisYear - year == 2 and month >= thisMonth)): # 爬取24个月内的信息 # if (thisYear == year and month == thisMonth and day == thisday): # 这里是设置时间的地方 #if (thisYear == year and month == thisMonth): if (thisYear == year): #if thisYear == year: return True else: return False def title_restraint(title,car_count, true_count): # 标题判断函数,判断标题中是否有所需要的“车”的内容 global most_kw_arr global pos_kw_arr global neg_kw_arr car_count += 1 if title.find(u"车") == -1: # or title.find(u"采购公告"): return False,car_count, true_count else: #car_count += 1 neg_sign = 0 pos_sign = 0 for neg_i in neg_kw_arr: if title.find(neg_i) != -1: # 出现了d_neg_kw中的词 neg_sign = 1 break for pos_i in pos_kw_arr: if title.find(pos_i) != -1: # 出现了d_pos_kw中的词 pos_sign = 1 break if neg_sign == 1: return False,car_count, true_count else: if pos_sign == 0: return False,car_count, true_count elif pos_sign == 1: true_count += 1 return True,car_count, true_count
将数据筛选完毕之后,对数据进行存储
def store(title, date, content, province, url): # 向nbd_message表存储车的信息 title, content = removeSingleQuote(title, content) sql = "insert into nbd_message (title,time,content,province,href) values('%s','%s','%s','%s','%s')" % ( title, date, content, province, url) return mySQL("pydb", sql, title, date, province)def store_nbd_log(car_count, true_count, province_file): # 向nbd_spider_log表存储爬取日志信息 sql = "insert into nbd_spider_log (total_num,get_num,pro_name,spider_time) values('%d','%d','%s','%s')" % ( car_count, true_count, province_file,str(datetime.date.today()) 流程结束
2.中国邮政
邮政的页面更加单一,但是邮政问题在于,
其每个单位都有单独的链接来展示其不同业务部门的招标信息,经过对比我发现,这个下属部门的首页链接,就差了最后一点不一样,因此我偷了个懒,多加了个循环
def main(): """ urls中分别对应着集团公司,省邮政分公司,邮政储蓄银行,中邮保险,集团公司直属单位 """ urls = ['7294-','7331-','7338-','7345-','7360-'] for i in range(0,len(urls)): strPost = '1.htm'#url后缀 base_url = "http://www.chinapost.com.cn/html1/category/181313/" + str(urls[i]) url = base_url + strPost html = get_one_page(url) # print(html) parse_one_page(html) page_num = getMaxpage(html) getMaxpage(html) for i in range(2,page_num + 1): next_url = base_url + strPost.replace('1',str(page_num)) next_html = get_one_page(next_url) parse_one_page(next_html) 邮政完成
3.国家电网
国家电网是我遇到的第一个问题,他的问题在于,在所需要的每个公告里面的href中,给出的不是通常的二级页面链接,而是JavaScript的两个参数,
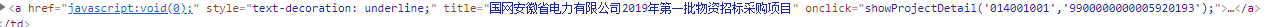
href=”javascript:void(0);”这个的含义是,让超链接去执行一个js函数,而不是去跳转到一个地址,而void(0)表示一个空的方法,也就是不执行js函数。为什么要使用href=”javascript:void(0);”javascript:是伪协议,表示url的内容通过javascript执行。void(0)表示不作任何操作,这样会防止链接跳转到其他页面。这么做往往是为了保留链接的样式,但不让链接执行实际操作, 点击链接后,页面不动,只打开链接 作用一样,但不同浏览器会有差异
而二级页面的链接与属性onclick里面的两个数字有关!!!因此我用onclick的两个参数,进行二级页面的拼接,
hrefAttr = selector.xpath("//*[@class='content']/div/table[@class='font02 tab_padd8']/tr/td/a/@onclick") for i in range(0,len(hrefAttr)): #获取二级页面的跳转参数,以便进行二级页面url拼接 string = str(hrefAttr[i]) attr1 = re.findall("\d+",string)[0] attr2 = re.findall("\d+",string)[1]
结语
继续搬砖......